
robots.txt 란?
robots.txt는 웹사이트에서 크롤링하며 정보를 수집하는 검색엔진 크롤러(또는 검색 로봇)가 액세스 하거나 정보수집을 해도 되는 페이지가 무엇인지, 해서는 안 되는 페이지가 무엇인지 알려주는 역할을 하는 .txt (텍스트) 파일

robots.txt 파일은 검색엔진 크롤러가 웹사이트에 접속하여 정보 수집을 하며 보내는 요청(request)으로 인해 사이트 과부하되는 것을 방지하기 위해 사용됩니다. robots.txt 파일은 도로에 있는 교통 표지판과 비슷한 역할을 한다고 이해할 수 있습니다. 가령 어떤 도로에 진입이 불가하다는 표지판이 있을 경우 진입하지 말아야 하는 것과 비슷합니다.
robots.txt이 필요한 이유
검색엔진 최적화 측면에서 보았을 때 robots.txt 파일을 적용해야 하는 이유는 크게 세 가지가 있습니다.
첫 번째는 앞서 간략하게 언급한 것 같이, 검색엔진 크롤러의 과도한 크롤링 및 요청으로 인한 과부하 방지를 위해서입니다. 크롤러의 정보 수집 및 크롤링을 제한함으로써 불필요한 요청을 줄이고, 서버에서 처리해야 하는 요청을 줄여 과부하로 인한 문제가 생기는 것을 방지할 수 있습니다.
두 번째는 검색엔진 크롤러의 일일 요청 수를 뜻하는 크롤 버짓 (또는 크롤링 예산 – Crawl budget) 낭비 방지를 위해서입니다. 검색엔진은 웹사이트에 방문해 정보를 수집할 때 웹사이트의 규모를 포함한 여러 가지 요소들을 고려하여 하루에 얼마나 많은 페이지를 방문 및 수집할지 설정합니다.

예를 들어 웹사이트에 1,000개의 페이지가 있고, 검색엔진이 일간 2,000 건의 요청 수를 보낸다고 한다면, 웹사이트에서 새로운 콘텐츠가 발행되거나, 업데이트가 있었을 경우 반나절이면 검색엔진이 변경사항에 대해 인지를 하게 된다고 볼 수 있습니다.
만약 robots.txt 파일에서 크게 중요하지 않거나 크롤링되지 말아야 하는 페이지를 지정하지 않는다면, 일일 크롤 버짓이 낭비될 수 있습니다. 결과적으로 정작 중요한 업데이트 또는 새로운 페이지가 검색엔진 결과에 반영되지 않거나 빠르게 색인되는데 불리합니다.
세 번째는 검색엔진 크롤러에게 사이트맵 (sitemap.xml)의 위치를 제공하여 웹사이트의 콘텐츠가 검색엔진에게 더 잘 발견될 수 있도록 하기 위해서입니다. 물론 구글 서치 콘솔이나 네이버 서치 어드바이저와 같은 웹마스터 도구를 이용해 사이트맵을 검색엔진에 제출할 수 있지만, robots.txt에 사이트맵 디렉토리를 언급함으로써 사이트맵이 구글과 네이버를 포함한 다른 검색 검색엔진 크롤러에게 빠르게 발견될 수 있습니다.
robots.txt를 창의적으로 이용하여 브랜딩 측면에서 좋은 이미지를 구축할 수 있습니다. 검색엔진 크롤러는 robots.txt의 표준 구문을 인식하고, 주석 처리된 문자열을 무시하기 때문에 이 특성을 이용하여 몇몇 글로벌 웹사이트들은 긍정적인 브랜드 이미지를 만드는데 robots.txt 파일을 사용하기도 합니다.
대표적으로 나이키 웹사이트와 에어비앤비 웹사이트를 예로 들 수 있습니다.
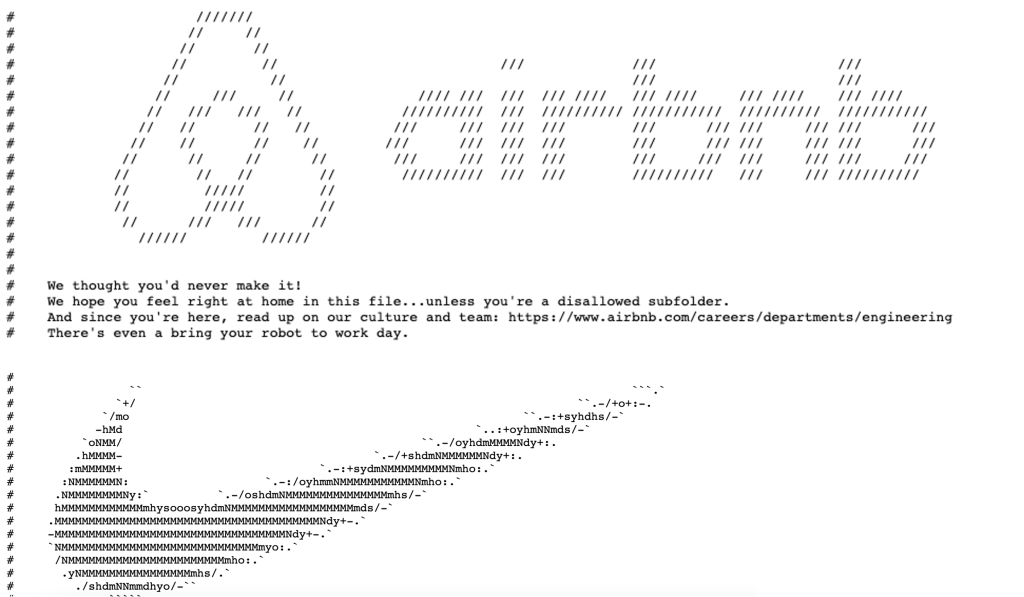
에어비앤비 나이키 robots.txt 파일
두 브랜드 모두 주석 처리된 문자열을 이용하여 브랜드 창의적으로 브랜드 로고를 노출하고 있으며,
에어비앤비의 경우 위트 있는 웹 엔지니어 구인 문구를 포함하고 있습니다.
robots.txt 작성하는 방법
robots.txt은 기본적으로 텍스트 파일( .txt )로 작성이 되어야 합니다. 그러기 위해서는 텍스트 파일을 편집할 수 있는 툴 (메모장, 텍스트 편집기, MS 워드) 등으로 robots.txt 파일을 작성한 뒤, .txt 파일 형식으로 저장하여야 합니다.
또한 robots.txt는 사람이 아닌 검색엔진 크롤러 (예: 구글봇, 네이버 예티, 빙봇 등)가 읽고 인식해야 하는 파일이기 때문에 정해진 형식과 문법에 따라 작성해야 합니다. 검색엔진 크롤러 별로 파일을 해석하는 방식이 조금씩 차이가 있다고 알려져 있으나, 기본적인 문법은 다르지 않습니다. 가장 기본적인 robots.txt 파일은 아래와 같은 형식을 가집니다.
#robots.txt 예시 - 기본 형식
User-agent: *
Disallow: /forbidden/
robots.txt 는 기본적으로 두 가지의 정보를 포함
- 위의 예시처럼 어떤 검색엔진 크롤러를 지정할 것인지 (User-agent 값)
- 어떤 디렉토리를 제한할 것인지 (Disallow 값)에 대한 정보를 지정
위의 robots.txt 기본 형식 예시는 모든 검색엔진 크롤러를 (User-agent: *) 모든 /forbidden/ 서브 폴더 이하 디렉토리의 크롤링을 제한한다 (Disallow: /forbidden/)라는 의미입니다.
robots.txt를 구성하는 요소는 크게 네 가지가 있습니다. 각각의 구성 요소를 모두 포함할 필요는 없지만 “User-agent”는 반드시 포함되어야 합니다.
- User-agent: robots.txt 에서 지정하는 크롤링 규칙이 적용되어야 할 크롤러를 지정합니다.
- Allow: 크롤링을 허용할 경로입니다 (/ 부터의 상대 경로).
- Disallow: 크롤링을 제한할 경로입니다 (/ 부터의 상대 경로).
- Sitemap: 사이트맵이 위치한 경로의 전체 URL입니다 (https:// 부터 /sitemap.xml 까지의 전체 절대경로 URL).
User-agent 이름은 검색엔진마다 모두 다릅니다. 가장 대표적으로 알려져 있는 구글 (Googlebot), 네이버 (Yeti), 빙(Bingbot), 야후 (Slurp) 외에도 각 검색엔진마다 User-agent 이름을 확인하여야 합니다. 아래는 자주 쓰이거나 영향력이 있는 서치 엔진별 크롤러 User-agent 이름 모음입니다. 웹사이트 크롤링 규정을 적용할 검색엔진 크롤러명을 지정하실 때 참고하시길 바랍니다.
- 구글: Googlebot
- 네이버: Yeti
- 다음: Daum
- 빙: Bingbot
- 덕덕고: DuckDuckBot
위 리스트에 포함된 검색엔진 크롤러 말고도 검색엔진별 크롤러의 이름은 모두 다르며, 검색엔진 업데이트 또는 리브랜딩의 이유로 크롤러 이름이 바뀌는 경우도 드물지만 종종 있는 일입니다. 그렇기에 robots.txt를 작성하기 전에 검색을 통해 검색엔진별 크롤러 이름을 먼저 확인하시기를 권장드립니다.
robots.txt 문법과 예시
robots.txt는 사람이 아닌 검색엔진 크롤러를 위한 파일이기 때문에 특정한 형식과 문법을 지켜 작성해야 합니다.
가장 기본적인 형태의 “User-agent”와 “Disallow”를 기본 뼈대로 여러 조합을 통해 특정 크롤러 별, 특정 디렉토리 별로 크롤링 제한을 적용할 수 있습니다. 이번 포스팅에서는 여러 가지 상황을 예제를 통해 살펴보겠습니다. 예제 부분을 복사하셔서 여러분의 웹사이트 디렉토리로 바꾸어 자유롭게 사용하셔도 좋습니다.
robots.txt 파일을 작성할 때 가장 기본적으로 명심하셔야 할 것은, robots.txt 파일에서 특정하게 명시하지 않은 크롤러와 디렉토리는 모두 크롤링이 가능한 것으로 간주됩니다. 그렇기 때문에 특별한 이유가 있는 것이 아니라면 따로 크롤링이 가능한 검색엔진 크롤러 또는 디렉토리를 지정할 필요가 없습니다 (그럼에도 불구하고 굳이 크롤링이 가능한 크롤러와 디렉토리를 명시해야 하는 경우가 있는데요, 본 포스팅 하단에서 다시 한번 짚고 넘어가겠습니다).
아래 robots.txt 예제는 가장 기본적인 형식인 모든 또는 특정 크롤러의 특정 폴더 이하 제한 문법입니다. 아래와 같이 모든 크롤러 (*) 또는 특정 크롤러명을 입력하면 됩니다.
# 대상: 모든 크롤러
# 제한 디렉토리: /do-not-crawl-this-folder/ 이하
User-agent: *
Disallow: /do-not-crawl-this-folder/
# 대상: 네이버 크롤러 (Yeti)
# 제한 디렉토리: /not-for-naver/ 이하
User-agent: Yeti
Disallow: /not-for-naver/
위의 기본 형식에서는 한 가지, 또는 모든 크롤러를 한 가지 디렉토리만 제한하는 문법이었는데요, 만약 복수의 크롤러가, 특정 디렉토리에서 크롤링하는 것을 제한하고 싶다면 어떻게 해야 할까요? 아래 예제와 같이 한 줄에 하나의 User-agent를 여러 개 적고, 제외할 디렉토리를 지정하면 됩니다. 여기서 주의해야 할 점은, 제한하고자 하는 크롤러를 모두 적은 뒤 디렉토리를 지정하는 “Disallow” 라인을 작성해야 한다는 점입니다.
# 대상: 네이버 크롤러 (Yeti) & 덕덕고 크롤러 (DuckDuckBot) & 다음 크롤러(Daum)
# 제한 디렉토리: /not-for-naver-and-duckduckgo-and-daum/ 이하
User-agent: Yeti
User-agent: DuckDuckBot
User-agent: Daum
Disallow: /not-for-naver-and-duckduckgo-and-daum/
앞선 두 가지 상황별 robots.txt 규칙을 잘 따라 해 보셨나요? 그렇다면 다수의 크롤러를 제한하되, 제한하는 크롤러마다 다른 디렉토리를 차단하고 싶은 경우는 어떻게 해야 할까요? 아래 예제와 같이 User-agent를 지정해준 뒤 개별적인 디렉토리를 지정해주면 됩니다.
# 대상: 네이버 크롤러 (Yeti)
# 제한 디렉토리: /not-for-naver/ 이하
# 대상: 덕덕고 크롤러 (DuckDuckBot)
# 제한 디렉토리: /not-for-duckduckgo/ 이하
User-agent: Yeti
Disallow: /not-for-naver/
User-agent: DuckDuckBot
Disallow: /not-for-duckduckgo/
앞선 예제들을 응용한 robots.txt 작성도 가능합니다. 예를 들어 네이버와 덕덕고는 같은 디렉토리 세 가지를 제한하고, 다음(Daum)은 두 가지 디렉토리를 제한하고 싶다면 어떻게 해야 할까요? 이번에는 여러분들도 잠시 시간을 가지고 작성해보신 뒤, 아래 예제에서 정답을 확인하시기를 제안드립니다. 아래 예제에서 답을 확인하세요.
# 대상: 네이버 크롤러 (Yeti) & 덕덕고 크롤러 (DuckDuckBot)
# 제한 디렉토리 1: /not-for-naver-and-duckduckgo-1/ 이하
# 제한 디렉토리 2: /not-for-naver-and-duckduckgo-2/ 이하
# 제한 디렉토리 3: /not-for-naver-and-duckduckgo-3/ 이하
# 대상: 다음 크롤러 (Daum)
# 제한 디렉토리 1: /not-for-daum-1/ 이하
# 제한 디렉토리 2: /not-for-daum-2/ 이하
User-agent: Yeti
User-agent: DuckDuckBot
Disallow: /not-for-naver-and-duckduckgo-1/
Disallow: /not-for-naver-and-duckduckgo-2/
Disallow: /not-for-naver-and-duckduckgo-3/
User-agent: Daum
Disallow: /not-for-daum1/
Disallow: /not-for-daum2/
앞서 robots.txt 에 지정되지 않은 크롤러와 디렉토리는 크롤링이 가능한 것으로 간주되기에 따로 “Allow” (크롤링 가능 디렉토리) 지정을 하지 않아도 된다고 언급한 부분 기억나시나요? Allow 디렉토리 지정의 경우 아래 예제와 같이 크롤링이 제한된 상위 서브 폴더 이하의 디렉토리 중, 특정 세부 디렉토리를 따로 크롤링 허용하고 싶을 때 사용하여야 합니다. 예를 들어, 강남구라는 구역을 제한했지만, 강남구에 속한 동 중 하나인 역삼동만 허용하고 싶을 때라고 이해하시면 쉽겠습니다.
# 대상: 네이버 크롤러 (Yeti)
# 제한 디렉토리: /not-for-naver/ 이하
# 허용 디렉토리: /not-for-naver/only-allow-here/ 이하
User-agent: Yeti
Disallow: /not-for-naver/
Allow: /not-for-naver/only-allow-here/
위의 세부 디렉토리 허용 예제에서 눈치채셨을지도 모르지만, Allow (디렉토리 허용)은 Disallow (디렉토리 차단) 보다 우선권을 갖습니다. 따라서 Allow를 사용하여 세부 디렉토리 크롤링 허용을 지정하게 될 때에는 의도치 않게 Disallow와 상충되지는 않는지 잘 살펴보아야 합니다. 아래는 잘못된 Allow 사용으로 Disallow 지정이 상충된 예시입니다. 아래와 같이 제한 디렉토리보다 상위 디렉토리를 허용하게 된다면, 지정된 제한 디렉토리는 허용 디렉토리와 상충되어 무효 처리됩니다.
# 대상: 네이버 크롤러 (Yeti)
# 제한 디렉토리: /folder-depth-1/folder-depth-2/ 이하
# 허용 디렉토리: /
User-agent: Yeti
Disallow: /folder-depth-1/folder-depth-2/
Allow: /
원하는 크롤링 제한 크롤러와 디렉토리 지정을 마쳤다면, 마지막으로는 사이트맵 위치를 명시해야 합니다. 사이트맵은 “Sitemap:”이라는 형식으로 포함할 수 있으며, 복수의 사이트맵 위치를 명시할 수 있습니다. 사이트맵 위치는 상대 주소를 사용하는 Disallow 또는 Allow 디렉토리와는 다르게, 절대 주소 (전체 URL) 포함해야 합니다. 아래는 사이트맵을 포함한 기본형 robots.txt 파일의 작성 예시입니다.
User-agent: *
Disallow: /do-not-crawl-here/
Sitemap: https://www.example.com/sitemap.xml
상황과 목적에 맞게 텍스트 작성을 모두 마쳤다면 텍스트 파일 (.txt) 로 저장, 이때 파일명은 반드시 robots.txt 여야 합니다.
업로드
robots.txt는 FTP를 이용하여 반드시 웹사이트의 루트 디렉토리 (웹사이트 주소에서 첫 번째 “/” 바로 뒤)에 업로드되어야 합니다.
https://naver.com/robots.txt 와 같이 최상위 디렉토리 루트에 존재해야 합니다. 다른 웹사이트의 robots.txt 파일을 참고해 보시려면 웹사이트의 루트 디렉토리에 /robots.txt를 입력하신 뒤 접속하시면 됩니다.
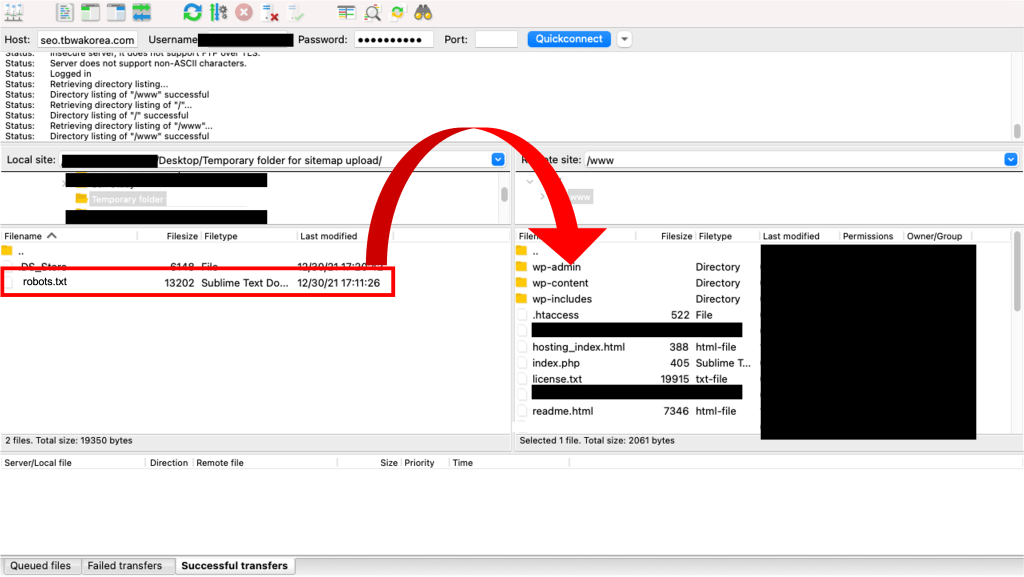
작성하신 robots.txt 파일 업로드까지 마무리되었다면, 업로드가 잘 되었는지 확인하는 일만 남았습니다. 인터넷 브라우저에서 여러분의 웹사이트 URL의 루트 도메인에 robots.txt를 입력하여 여러분이 작성한 robots.txt 파일이 잘 보이는지 확인해보세요.
robots.txt에서 제한 디렉토리를 설정했는데 색인이 생성되었어요 왜 그런 거죠?
구글을 포함한 대부분의 검색엔진은 robots.txt에서 제한하는 디렉토리나 페이지를 크롤링하지 않습니다. 다만 제한된 디렉토리 또는 페이지 URL이 웹 상의 다른 곳에 연결된 경우 (예: 다른 웹사이트에서 백링크를 주고 있는 경우) 색인이 생성될 수 도 있습니다.
만약 페이지가 색인되지 않길 원한다면 HTML 소스코드 <head></head> 안에 <meta name=”robots” content=”noindex”> 라인을 추가해주세요.
robots.txt 파일에 크롤링을 제한할 디렉토리를 명시하면 자동으로 모든 접근 차단이 되나요?
그렇지 않습니다. robots.txt 파일은 검색엔진 크롤러를 위한 지침사항일 뿐이며, 접근을 차단하거나 리소스를 보호하는 역할을 하지 않습니다. 웹사이트에서 접근을 차단하거나 보호해야 할 페이지 또는 비공개 리소스가 있을 경우 ip 기반으로 접근을 차단하거나 비밀번호를 지정하는 등의 차단 방식을 적용해야 합니다.
robots.txt 파일에 크롤링을 제한할 모든 디렉토리를 추가해야 하나요?
웹사이트에서 접근을 차단하거나 보호해야 할 디렉토리 / 페이지 / 비공개 리소스가 있을 경우 noindex tag 적용, ip 기반 접근을 차단, 또는 비밀번호를 지정하는 등의 차단 방식을 지정하고 robots.txt 파일에는 명시하지 않아야 합니다.
robots.txt 파일에서 크롤링을 제한하는 디렉토리 URL 은 대소문자를 구분하나요 (Case-Sensitive)?
네, 그렇습니다. 그렇기 때문에 크롤링을 제한할 URL에 대소문자가 혼합되어 사용되고 있다면 대소문자 그대로 작성해야 합니다.
robots.txt 파일에서 크롤링을 제한할 User-agent의 순서가 상관이 있나요?
그렇지 않습니다. User-agent를 구체적으로 언급하고 상충되지 않게 작성하였다면 명시 순서는 중요하지 않습니다.
아키라 AKIRA 원작과 애니메이션
무너진 도쿄, 그리고 비밀 프로젝트! 원작 만화 오토모 카츠히로가 1982년부터 1990년까지 코단샤의 청년대상 만화잡지 〈영 매거진〉에 연재한 사이버펑크에 영향을 받은 만화로 출판사에서 선
phillipoh.tistory.com
비슷한 듯... CPU, GPU, NPU, TPU의 차이점
CPU, GPU, NPU, TPU 인공지능(AI) 개발에 필수적인 머신러닝에는 GPU, NPU, TPU 등의 프로세싱 칩이 사용되고 있다. 많다 복잡하다. 내가 아는 것은 CPU, GPU... 각각의 차이점을 알기 쉽지 않다. 구글과 클라
phillipoh.tistory.com
스티브 잡스 vs 빌 게이츠
우리가 일반적으로 스티브잡스는 롤모델이면서 본받아야하는 1순위 형님. 빌게이츠는 돈밖에 모르는 촌놈.. 이라고 알고 있다. 그냥 재미삼아 정리된 짤이지만 사실은 아래에 잘 정리되어 있다.
phillipoh.tistory.com
2024년 AI 특이점(Singularity) 온다.
갈수록 진화하는 AI, 2024년 '특이점' 오나 오픈AI의 AGI 개발 ‘Q스타 프로젝트’ 세계 테크업계 화두로 ‘특이점(Singularity)’이 떠오르고 있다. 인공지능(AI)이 인간과 같거나 그 이상으로 변하는
phillipoh.tistory.com
셀럽들의 안티 SNS, 바보폰 '덤폰' (Dumb Phone)
집중력, 창의력 키우려 플립폰 쓰는 MZ세대 래퍼로는 처음으로 퓰리처상을 수상한 힙합 뮤지션 켄드릭 라마(37)는 이달 초 미국 ‘덤폰(Dumb phone)’ 제조업체 라이트와 손잡고 ‘라이트 폰 2′ 한
phillipoh.tistory.com






